HTTP and RESTFul APIs 중 HTTP
이해 및 정리를 쉽게 하고 싶어서 작성한겁니다! 그렇기에 제가 참고한 글을 매우 정확하게 보여드리기 위해 밑에 원문 자체로 복사해서 가져왔습니다. 이미 다 알고 계신분은 밑에 참고원문을 보고 이해하시면 좋을 것 같습니다 :)
Http는 프로토콜입니다. 프로토콜은 컴퓨터 사이나 중앙 컴퓨터와 단말기 사이에서 데이터 통신을 원활하게 하기 위한 통신 규약(약속)입니다. 그러면 HTTP는 어떤 약속이냐면 웹에서 이루어지는 모든 데이터 교환의 기초입니다.
프로토콜은 총 7개의 레이어로 구성되어 있습니다. 그냥 전세계가 약속했습니다. 모든 통신은 7개의 층으로 만들어서 하자고 프로토콜을 OSI에서 규정했습니다. OSI 7계층에 대해서 자세히 말하진 않겠지만 HTTP도 이 중 하나의 레이어(계층)에서 통신이 이루어 지는 클라이언트-서버관계의 프로토콜입니다.
여담으로 요즘 웹사이트 주소를 보면 HTTPS가 붙었는데 이것은 보안 버전입니다. 다시 정리하면 HTTP는 웹에서 클라이언트와 서버관계의 데이터를 주고 받는 프로토콜인데 HTTPS는 HTTP와 같은 일을하면서 보안까지 추가 된 버전이라고 생각하면 됩니다.
HTTP를 조금 만 더 자세히 살펴보면 HyperText Transfer Protocol의 약자입니다. 앞선 설명에서 빠진 단어는 아무래도 HyperText인거 같습니다. HyperText는 간단하게 하이퍼 링크를 나타낼 수 있는 텍스트입니다. 이렇게 짧게만 설명하면 너무 추상적인거 같습니다. 조금더 부연 설명을 하자면 HTML을 예시로 설명 가능할 것 같습니다. HTML은 HyperText Markup Language의 약자로 HyperText를 위한 마크업 언어 입니다.
메모장을 켜서 그냥 Hello World라고 작성하고 다른이름 저장을 누른 뒤 파일확장자를 ‘테스트.html’이라고 저장하고 파일을 누르면 웹브라우저가 열리면서 Hello World가 나올 겁니다! 즉 HTML은 문서의 구조, 우리가 보고 있는 웹 화면의 구조를 잡는 언어입니다.
저희는 간단하게 한줄만 작성했지만 구조를 작성했고 클라이언트가 이 파일을 요구하면(requests) 서버는 응답할겁니다(responses) 여기서 저희가 작성한 ‘테스트.html’의 클라이언트는 제 손이고 서버는 제 컴퓨터겠죠 :) (너무 진지하게 얘기하면 어려워지니 여기까지)
그러면 다시 HTTP는 뭐야? 라고 물어보면 클라이언트는 저기 미국에서 사는 제 친구가 방금 제가 처음으로 코딩한(?) ‘테스트.html’을 구경해보고 싶고 한국에서 이걸 작성하고 있는 제 컴퓨터가 서버가 되겠죠? 이걸 가지고 왔다갔다 할 교통수단이 필요하고 이것이 HTTP라고 부를 수 있을 것 같습니다.
방금 들었던 예시중에 가장 중요한 것이 빠져있는데 어떤게 있을까요? 방금 HTTP가 하나의 교통수단이 된다고 했는데 바다가 있거나, 땅이 있거나, 하늘이 있어야 교통수단이 의미가 있을텐데. 이를 브라우저라고 합니다. 웹 브라우저는 HTTP가 타고 놀 수 있는 장소라고 생각하면 좋을 것 같습니다. 인터넷 상에 어디든 갈 수 있도록 브라우저는 웹의 다른 곳에서 정보를 가져와 사용자의 데스크탑이나 모바일 장치에 보여줍니다. 브라우저는 사파리, 크롬 같은 저희가 자주 사용하는 인터넷을 사용하기 위한 것입니다.
HTML + CSS + JS + File들로 작성 된 Web document를 인터넷 세상 브라우저를 통해 web server, ads server, video server로 보내고 있는데 (일단 각 server에 대해 의문만 가진 채 넘어가서 설명하겠습니다) 어떻게 보내지? 라는 의문 먼저 생각해보겠습니다.
!https://developer.mozilla.org/ko/docs/Web/HTTP/Overview/http-layers.png
{kind=link}
클라이언트의 요청 : requests - 클라이언트가 서버에게 요청을 보낼 때 HTTP는 요렇게 보냅니다.
- HTTP 메서드, 보통 클라이언트가 수행하고자 하는 동작을 정의한 GET, POST 같은 동사나 OPTIONS나 HEAD와 같은 명사입니다. 일반적으로, 클라이언트는 리소스를 가져오거나(GET을 사용하여) HTML 폼 (en-US)의 데이터를 전송(POST를 사용하여)하려고 하지만, 다른 경우에는 다른 동작이 요구될 수도 있습니다.
- 가져오려는 리소스의 경로; 예를 들면 프로토콜 (http://), 도메인 (여기서는 developer.mozilla.org), 또는 TCP 포트 (여기서는 80)인 요소들을 제거한 리소스의 URL입니다.
- HTTP 프로토콜의 버전.
- 서버에 대한 추가 정보를 전달하는 선택적 헤더들.
- POST와 같은 몇 가지 메서드를 위한, 전송된 리소스를 포함하는 응답의 본문과 유사한 본문.

정말 이렇게 보냅니다.
물론 정말 HTTP 위에 저렇게 보내는게 아니라 테이블 형식의 2진수 형태로 우루루루우룰우루울우루 보냅니다. 완전 신기합니다.
그래서 그림들 보면 다 이상한 형태로 그려져 있을겁니다. 이유는 아래와 같습니다. 맨 처음 HTTP는 사람도 알아볼 수 있도록 글로 작성되어 있었는데 이게 조금 문제가 많아서 HTTP가 버전이 올라가면서 이진구조로 변경되었습니다.
왼쪽 순서로 나가기 때문에 그림도 저렇게 그린겁니다. 그림안에 이런 데이터들이 들어갑니다!
서버의 응답 : responses - 클라이언트가 보낸 요청을 보고 맞춰서 응답을 보내는 틀 보통 모두 Header + body로 구성
- HTTP 프로토콜의 버전
- 요청의 성공 여부와, 그 이유를 나타내는 상태 코드
- 아무런 영향력이 없는, 상태 코드의 짧은 설명을 나타내는 상태 메시지
- 요청 헤더와 비슷한, HTTP 헤더들
- 선택 사항으로 가져온 리소스가 포함되는 본문
이렇게 헤더를 통해서 한국에서 미국까지 인터넷을 하기위해 패킷의 까보면서 이동합니다. 그리고 헤더의 메서드 들을 이용하여 더욱 빠르게 클라이언트는 간단하게 서버에게 요청의 카테고리를 나눌 수 있습니다. 서브웨이 처럼 요청이 많으면 알바생이 점점 눈물을 흘리기때문에 서버도 마찬가지입니다. 그래서 약속을하고 클라이언트가 서버에게 요청할때 메서드들을 나눴습니다!
GET
GET 메서드는 대상 리소스의 상태 표현을 전송하도록 요청합니다. GET 요청은 데이터 검색만 수행해야 하며 다른 영향을 미치지 않아야 합니다. (다른 HTTP 메서드도 마찬가지입니다.) 리소스를 변경하지 않고 검색하려면 URL을 통해 주소를 지정할 수 있으므로 POST보다 GET이 선호됩니다. 이를 통해 북마크와 공유가 가능하며, GET 응답은 캐싱이 가능하여 대역폭을 절약할 수 있습니다. W3C](https://en.wikipedia.org/wiki/W3C)는 이러한 차이에 대한 지침 원칙을 발표하여 "웹 애플리케이션 설계는 위의 원칙뿐만 아니라 관련 제한 사항도 고려해야 합니다.
HEAD
HEAD 메서드는 GET 요청과 마찬가지로 대상 리소스의 상태 표현을 전송하도록 요청하지만, 응답 본문에는 표현 데이터를 포함하지 않습니다. 이는 전체 표현을 전송할 필요 없이 응답 헤더에서 표현 메타데이터를 검색하는 데 유용합니다. 상태 코드](https://en.wikipedia.org/wiki/HTTP_status_code)를 통해 페이지를 사용할 수 있는지 확인하고, 파일의 크기(Content-Length)를 빠르게 찾는 등의 용도로 사용할 수 있습니다.
POST
POST 메서드](https://en.wikipedia.org/wiki/POST_(HTTP))는 대상 리소스가 요청에 포함된 표현을 대상 리소스의 시맨틱에 따라 처리하도록 요청합니다. 예를 들어, 인터넷 포럼에 메시지를 게시하거나, 메일링 리스트에 가입하거나, 온라인 쇼핑 거래를 완료하는 데 사용됩니다.
PUT
PUT 메서드는 대상 리소스가 요청에 포함된 표현에 정의된 상태로 상태를 생성하거나 업데이트하도록 요청합니다. 클라이언트가 서버의 대상 위치를 지정한다는 점에서 POST와 구별됩니다.
DELETE
DELETE 메서드는 대상 리소스의 상태를 삭제하도록 요청합니다.
CONNECT
CONNECT 메서드는 요청 대상에 의해 식별된 원본 서버에 대해 중개자가 TCP/IP 터널을 설정하도록 요청합니다. 하나 이상의 HTTP 프록시를 통해 TLS로 연결을 보호하는 데 자주 사용됩니다.
OPTIONS
OPTIONS 메서드는 대상 리소스가 지원하는 HTTP 메서드를 전송하도록 요청합니다. 특정 리소스 대신 '*'를 요청하여 웹 서버의 기능을 확인하는 데 사용할 수 있습니다.
TRACE
TRACE 메서드는 대상 리소스가 수신한 요청을 응답 본문으로 전송하도록 요청합니다. 이를 통해 클라이언트는 중개자가 변경하거나 추가한 내용을 확인할 수 있습니다.
PATCH
PATCH 메서드](https://en.wikipedia.org/wiki/PATCH_(HTTP))는 요청에 포함된 표현에 정의된 부분 업데이트에 따라 대상 리소스의 상태를 수정하도록 요청합니다. 이렇게 하면 파일이나 문서를 완전히 전송할 필요 없이 일부만 업데이트하여 대역폭을 절약할 수 있습니다.
모든 범용 웹 서버는 최소한 GET 및 HEAD 메서드를 구현해야하며 다른 모든 메서드는 사양에 따라 선택 사항으로 간주됩니다.
이 메서드들은 한번씩 읽어보고 가능하다면 기억해두는 게 좋지만 여기서 중요한건 멱등성 Idempotent입니다.
개발과 매우 직관적으로 연결되어 있는 부분이기 때문에 자세하게 이해하고 넘어가는게 제일 좋습니다! 실은 외우는게 제일 좋지만 지금은 이런게 있구나 생각하고 넘어가도 괜찮습니다. 웹 개발 들어가는 순간, API를 만드는 순간 이 표를 보러 다시 달려올 거기 때문입니다. 걱정안하셔도 돼요!
지금까지 HTTP의 요청 메소드를 봤으면 이제는 응답부분을 살펴보겠습니다! 여기는 완전 자주 본 숫자일 수도 있습니다.
웹페이지를 들어가다 나올때마다 가끔 404 오류를 본 적이 있을겁니다. 그리고 만약 대학생이라면 500도 볼 수도 있겠네요(수강신청할때, 티켓팅할때?) 저희가 열심히 광클을 한 기억이 있을 수도 없을 수도 있지만 임영웅, 아이유 님들의 티켓팅을 할때 웹 개발자들은 500 오류를 정말 열심히 잡기 위해 노력합니다. 막 광고에서 로드밸런싱, 10만 트래픽 이야기를 하는데 HTTP 요청에 대한 응답의 코드는 아래와 같습니다.
**1XX(정보 제공) 요청이 수신되어 처리 중
2XX(성공) 요청이 성공적으로 수신되어 이해 및 수락됨
3XX(리디렉션) 요청을 완료하려면 추가 조치가 필요함
4XX(클라이언트 오류) 요청에 잘못된 구문이 포함되어 있거나 처리할 수 없음
5XX`(서버 오류)** 서버가 명백히 유효한 요청을 처리하지 못했습니다.
왜 500 응답을 안보내기 위해 백엔드 개발자들이 야근하면서 잡는지 조금은 감이 오실까요? 404는 클라이언트 오류(물론 개발자 잘못)도 있겠지만 500은 명백한 개발자 잘못입니다… 아니 컴퓨터 잘못인데 왜 내 잘못으로 된거지 난 잘못이 없다. 어쨌든 이를 해결하기 위해 HTTP는 여러가지 기능들을 제공(?)합니다.
아 그전에 하나 당연하지만 알아야 하는 것이 있습니다! HTTP는 브라우저에서 일어나는 모든 일에 대한 책임을 가지고 있는 친구가 아닙니다!!! 완전 약한 친구입니다. (아닌가 다 두들겨맞으면서 가니깐 강한건가..?) 어쨌든 서버와 클라이언트가 브라우저를 통해 HTTP라는 프로토콜로 대화를 나눈다라고 예시를 들었지만 OSI 레이어를 통해 또 역할이 세분화하게 나뉩니다. 다시 얘기하자면 HTTP는 서버와 클라이언트의 연결을 담당하진 않습니다.
그건 전송계층에는 아까 얘기했던 TCP와 UDP가 있습니다.(와후! 맨 처음에 설명한거 같아요)
아까 맨처음 TCP와 UDP는 신뢰성이 있는 데이터를 보내냐 안보내냐를 이야기 한 것 같습니다. 조금만 더 풀어서 이야기 하자면 TCP는 수많은 인터넷 세상을 헤쳐서 데이터를 보낼 때 논리적 경로를 배정합니다. 서울에서 부산까지만 해도 저희는 각자 다른 길로 갑니다!
물론 큰 고속도로에서 만날 수는 있지만 누구는 버스 전용차로 누구는 경차 전용차로, 기차, 비행기 각자 가는 방법이 다릅니다! 하지만 TCP는 무조건 가족 전체가 차례대로 부산이 오길 기대하고 있기에 데이터의 순서를 이용하여 하나도 빠짐없이 정해진 길로 냅다 와~의 형식이라면 UDP는 그냥 오라고 손짓합니다. 알아서 그냥 도착만해~ 형식입니다.
이를 다시 현실적인 예시로 정리하자면 UDP는 스트리밍 서비스에서 많이 사용합니다. TCP는 조금 힘듭니다 스트리밍하기엔 어쨋든 깊게 들어가면 들어갈수록 더 깊어지는 얘기니깐 여기까지만 얘기하겠습니다.(자세한 개념 및 전문성 넘치는 글은 여러 블로그들 참고하세요!)
어쨋든 TCP도 UDP도 어떠한 기능들이 있는데 HTTP는 어떤 제어기능이 있을까 살펴보려고 이야기가 길어졌습니다! 그러면 HTTP로 할 수 있는 일은 다음과 같습니다.
- 캐시
- origin 제약사항 완화
- 인증
- 프록시와 터널링
- 세션
정도가 있습니다.
이걸 자세히 들어가면 굉장히 어려워지긴 하지만 간단하게 얘기해보겠습니다. 일단 캐시!
캐시는 서버지연을 막기 위해서 사용하고 있습니다. 네이버를 들어가면 엄청나게 많은 이미지와 글들이 있는데 이를 1분에 5천명이 글을 원한다고 하면 생각만해도 컴퓨터가 엄청 좋아도 다 못보여줄거같습니다. 하지만 한번 불러오면 캐시를 통해 리소스의 복사본을 저장하고 있다가 다시 요청시에 그것을 제공하는 역할을 합니다. 실제로 많은 상황에서 캐시가 도움이 되기도 문제가 되기도 합니다.
예를들어 결제창에서 새로고침을 누르지 말라는 경고창이 심심치 않게 보이는데요 이건 본인, 클라이언트의 캐시가 결제를 방해할 수도 있기 때문입니다!
두번째는 origin 제약사항을 완화입니다.
이 부분은 웹개발을 한번이라도 해본 사람이라면 당해봤을 부분입니다. CORS 익명 매우 높죠. 이 문제는 조금만 검색해봐도 세상 많은 웹 개발자들이 해결하려고 적어논 글 투성이 일겁니다. 이 오류가 생기는 이유는 http origin 정책 때문입니다!!!! 매우 간단한 이야기인데 스누핑(나쁜 해킹 방식 중 하나)과 다른 프라이버시 침해를 막기 위해 브라우저는 웹 사이트 간의 엄격한 분리를 강제합니다!!! 뭐든 보안에 강제가 높다면 성능을 떨어지겠죠.. 하지만 HTTP 헤더를 통해 이 부분을 완화시킬 수 있다는 말입니다.! 더 궁금하다면 Same-Origin Policy, CORS를 치면 더욱 자세히 알 수 있습니다.
세번째는 인증인데 특정 사용자만이 접근하게 만드는 방법에 대해 설명합니다. http 헤더에 특정 인증 헤더를 넣어서 요청을 보내면 되는건데 이것도 간단하게만 알고 넘어가면 괜찮습니다.(나중은 안괜찮습니다)
네번째는 프록시와 터널링입니다.
프록시와 터널링 개념은 조금 많이 중요합니다. 간단히 설명하면 프록시는 서버와 클라이언트 사이에 있는 뭐랄까… 표지판..? 우편함..? 중개인이라고 생각하면 편할 거 같습니다. 서버한테 가기전에 한번 쯤 검토하고 서버한테 보내준다고 생각하면 편할 거 같습니다. 프록시 선생님은 굉장히 중요합니다. 왜냐면 HTTP는 TCP기반이기 때문이죠! 만약 제가 나쁜 마음을 먹고 HTTP에 악성 코드를 넣어서 보내면 클라이언트들은 당하고 말겁니다. 근데 다들 안당하시죠? 프록시 선생님을 어떻게 하냐에 따라 엄청난 서버의 수문장이 될수도 서버의 부하를 나눌 수도 있을겁니다! 터널링은 VPN과 같은 상황입니다. 가상의 통로로 거쳐가는 인터넷 수많은 게이트웨이들은 데이터를 볼수도 건들수도 없습니다. 이건 네트워크 통신에 더 가까운 개념으로 가긴하는데 어쨌든. HTTP는 이런일도 하는구나를 알고 있으면 좋습니다. 그리고 꿀팁은 프록시와 터널링의 개념은 꼭 한번은 짚고 넘어간다면 웹 개발을 할때 굉장히 도움이 많이 될겁니다!
다섯번째는 세션입니다! 이것도 굉장히 많이 중요해요
제일 중요한 HTTP의 특징이 여기서 나옵니다. HTTP 상태없는 프로토콜입니다. 이게 무슨 말이냐면 클라이언트가 요청하거나 서버가 응답할때 보내면 남의 자식이라는 겁니다. 이제 그 친구는 사회로 나가 절대 찾을 수 없는 망망대해에 버려버린겁니다. 잘가든 못가든 나는 보냈다 받을거면 받아라 이런 느낌의 프로토콜이거든요 근데 왜 나의 웹사이트 쇼핑몰에는 장바구니가 유지되고 자꾸 검색기록을 저장해서 추천 광고를 누가 주는거지? 하면 범인은 세션입니다. 집나간 데이터들을 일단 계속 놀자고 붙잡고 있는 착하지만 위험한 친구거든요. 좀 더 명확하게 얘기하면 클라이언트가 세션 ID를 저장하고 서버에게 요청할 때 세션 ID를 함께 보냅니다. 그러면 서버는 클라이언트를 식별할 수가 있고 해당 세션에 연결된 상태정보를 찾을 수 있게 되는겁니다!
더 자세한 얘기는 마찬가지로 블로그 치면 5억개 나와욥. 참고로 여기서 쿠키를 궁금해할수도 있습니다! 맨날 쿠키 세션 이런 얘기하는데 저랑 비슷한 나이대는 알지도 모르겠지만 옛날 인터넷 들어가면 쿠키 허용 막 엄청 뜨고 그랬는데.. 라떼는… 어쩃든 쿠키는 세션과 비슷한 역할인데 쿠키는 내 컴퓨터 어딘가에 저장되어 있는 작은 데이터 단위이고 세션은 서버에서 관리한다는 점에서 차이가 있습니다. 나머지는 진짜 비슷해요 그냥 거기서 거기 입니다.
HTTP 스토리 라인
An overview of HTTP - HTTP | MDN
HTTP 더 자세한 내용
An overview of HTTP - HTTP | MDN
HTTP Requests Method에 대한 내용
[HTTP] HTTP 메소드의 멱등성(Idempotence)과 Delete 메소드가 멱등한 이유
쿠키랑 세션 개념

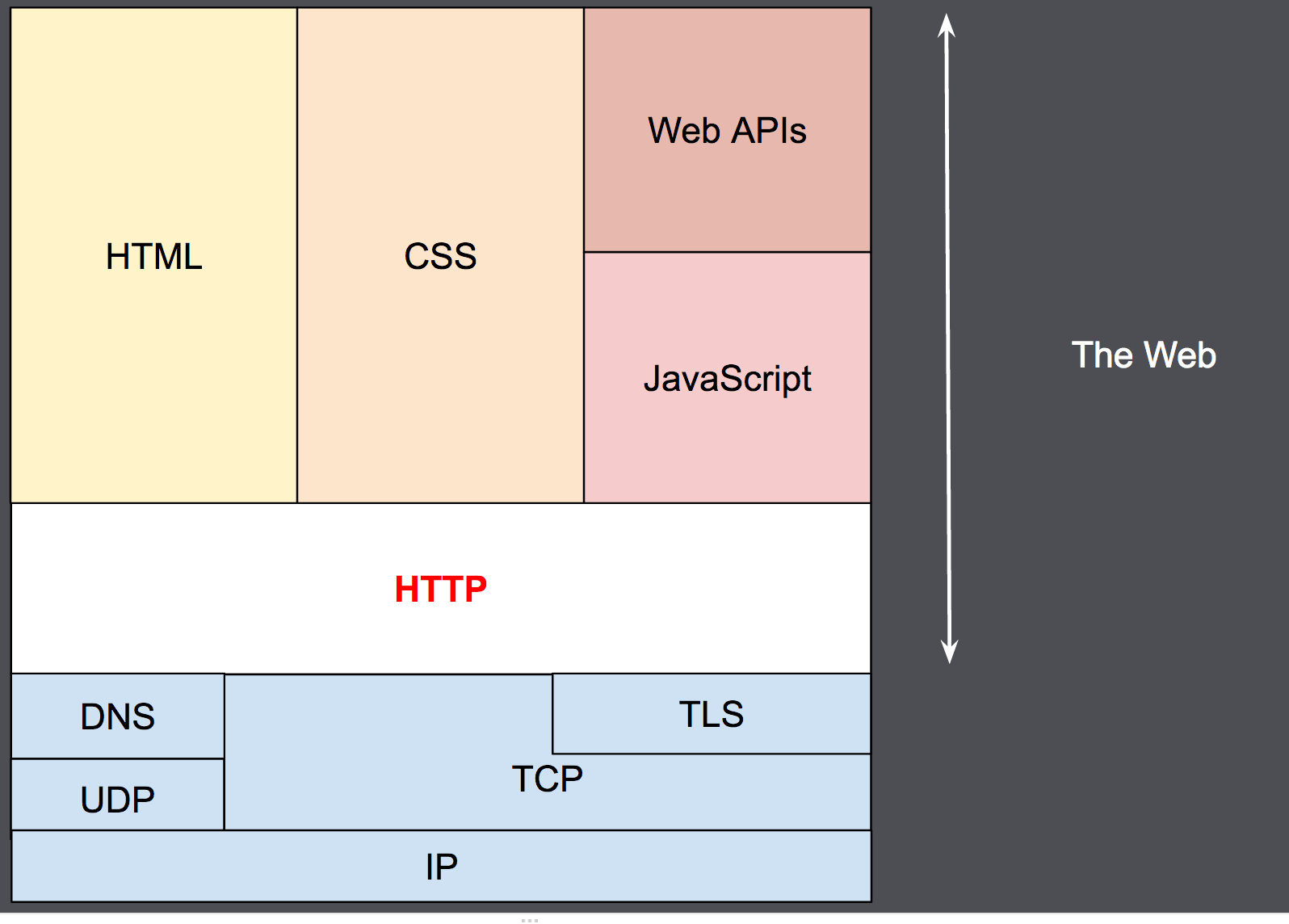
이렇게 되니깐 압축도 가능하고(0000000000000000000000110101 이면 0을 어떤 기준에따라 압축하면 되겠쬬?) 어쨌든 이걸 설명한 이유는 HTTP는 TCP/IP, UDP/IP 위에 위치한다는 겁니다. HTTPS도 마찬가지로 SSL/TLS를 통해 HTTP가 S로 붙여지는 이유입니다. 그럼 여기서 모르는 단어들은 당연히 UDP와 TCP, DNS TLS가 있을겁니다.
간단히 설명하면 DNS는 192.168.219.1 의 형식의 주소를 www.naver.com으로 변경해주는 걸로 알고 계시고 TCP와 UDP는 서버와 클라이언트의 데이터 전송의 신뢰성을 보장할까? 말까?를 결정하는 프로토콜입니다.(뒤에 P붙으면 다 프로토콜이에요) TCP랑 UDP 얘기만으로도 진짜 한학기 대학 수업 가능이지만 이는 다음으로 미뤄두고 간단하게만 알고 계시면 될 거 같습니다! 그리고 TLS는 네트워크 보안 프로토콜입니다. 이정도만 아셔도 진짜 충분합니다. 지금은! HTTP가 뭔지 감을 잡는게 중요하기 때문입니다 🙂